Pamięci skojarzeniowe
Wiodącym obszarem zastosowań modelu dyskretnego jest
konstruowanie pamięci skojarzeniowych, w których
komórki pamięci adresowane są poprzez
swoją zawartość a nie za pomocą określonego adresu.
Zadaniem pamięci skojarzeniowej jest zapamiętanie danego zbioru
wzorców binarnych w taki sposób, żeby po otrzymaniu na wejściu nieznanego
wzorca binarnego ![]() pamięć odtwarzała na wyjściu ten z zapamiętanych
wzorców, który jest najbliższy
pamięć odtwarzała na wyjściu ten z zapamiętanych
wzorców, który jest najbliższy ![]() w sensie odległości Hamminga
(patrz ramka). Inaczej
formułując problem, pamięć skojarzeniowa powinna spełniać dwa warunki:
w sensie odległości Hamminga
(patrz ramka). Inaczej
formułując problem, pamięć skojarzeniowa powinna spełniać dwa warunki:
- pokazanie na jej wejściu dowolnego z zapamiętanych wektorów (wzorców) powoduje odtworzenie na wyjściu tego samego wektora,
- pokazanie na wejściu zaburzonej (,,w rozsądnych granicach'') wersji dowolnego z zapamiętanych wektorów powoduje odtworzenie na wyjściu poprawnej postaci tego wektora.
|
|
Metodę konstruowania pamięci skojarzeniowej podaną przez Hopfielda
można streścić następująco. Rozważmy
zbiór ![]() złożony z
złożony z ![]() wzorców bipolarnych (tzn. o elementach
należących do zbioru
wzorców bipolarnych (tzn. o elementach
należących do zbioru ![]() )
)
![]() o długości
o długości ![]() każdy.
każdy.
|
Pamięć skojarzeniowa służąca do zapamiętania wzorców ze zbioru ![]() zbudowana jest z
zbudowana jest z ![]() neuronów
neuronów
![]() .
Kwadratowa macierz połączeń
.
Kwadratowa macierz połączeń ![]() o wymiarach
o wymiarach ![]() obliczana jest za
pomocą tzw. reguły Hebba:
obliczana jest za
pomocą tzw. reguły Hebba:
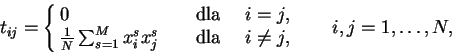
gdzie
|
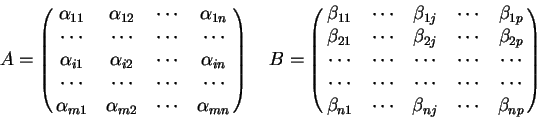

Przykładowo, dla zbioru wzorców
![]() macierz
macierz ![]() otrzymana przy
zastosowaniu reguły Hebba wygląda następująco:
otrzymana przy
zastosowaniu reguły Hebba wygląda następująco:
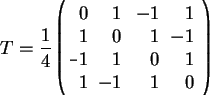
Rozpoznawanie wzorców z wykorzystaniem nauczonej sieci przebiega w
następujący sposób. Nieznany wzorzec
![]() jest
pokazywany w warstwie wejściowej sieci, a następnie wszystkie neurony
jest
pokazywany w warstwie wejściowej sieci, a następnie wszystkie neurony
![]() obliczają swoje potencjały wejściowe
obliczają swoje potencjały wejściowe ![]() , oraz
wyjściowe
, oraz
wyjściowe ![]() , tj.
, tj.

Wracając do naszego przykładu, można łatwo policzyć (zostawiamy to jako ćwiczenie !), że wskazanie na wejściu dowolnego z wektorów
[ Początek strony ] [ MiNIWyklady ]