What is GGP?
General Game Playing (GGP) is a research area concerned with a design of autonomous programs capable of playing a variety of games, including the ones they have never encountered before. This project refers to the particular embodiment of the GGP idea proposed by Stanford University in 2005. Since then, an annual GGP competition has been organized, that brings an additional challenge, excitement and the way to define the current trends in the field. The competitors, i.e. computer programs, are given the rules of games at run-time and have to figure out how to play without any human intervention. Therefore, they need to combine various interesting aspect such as knowledge extraction and representation, efficient state-search, abstract reasoning and decision making.
Here are some good introductions to the problem:
- http://logic.stanford.edu/ggp/chapters/chapter_01.html
- http://games.stanford.edu/index.php/what-is-ggp
- http://www.general-game-playing.de/
- http://www.ggp.org/docs/BeginnersGuide.html
The rules are written in the so-called Game Description Language (GDL). Any finite, deterministic, perfect-information synchronous game can be encoded in GDL. The official language specification can be found here.
What is MINI-Player
MINI-Player is our GGP agent. It was the first player from Poland (ax-aequo with Magician) to participate in the GGP Competition and the first one to reach the final day of this tournament (in 2012).
In 2012, MINI-Player has advanced to the final day of the completion with the 5th best score. The final place was 7th. In 2013, it encountered some issues with single-player games and ended the tournament as 11-th not qualifying to the final day. In 2014, there were a record number of 49 players submitted to the qualifying round of the competition thanks to a massive online open course about GGP. Our player, together with 16 other ones, successfully went through the qualification round. Then it reach the final day with 11 other players. It managed to eliminate one opponent (2-0) but lost against two (1-2, 1-2) in a double-elimination format and finished the competition on the 7-8th place.
The major parts and contributions of MINI-Player:
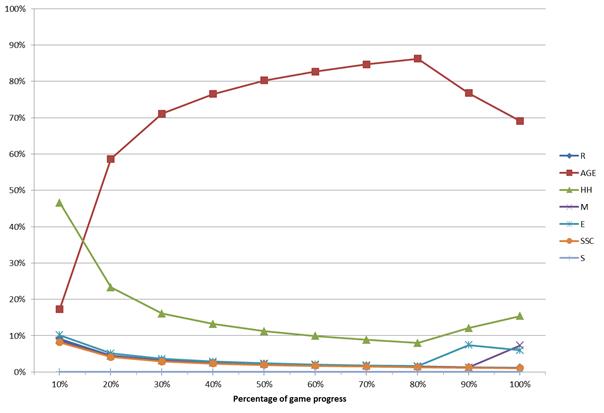
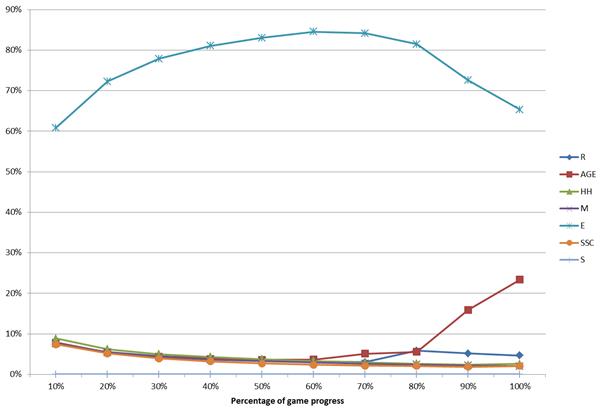
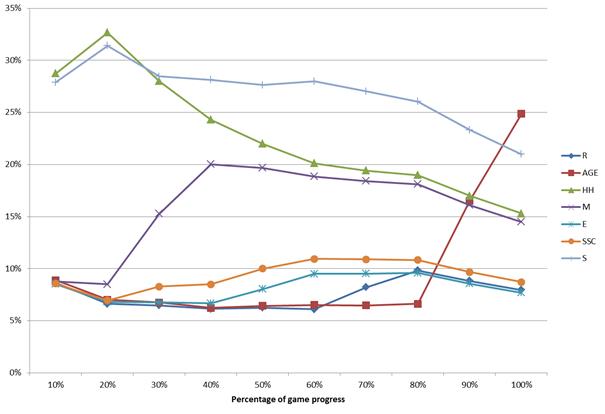
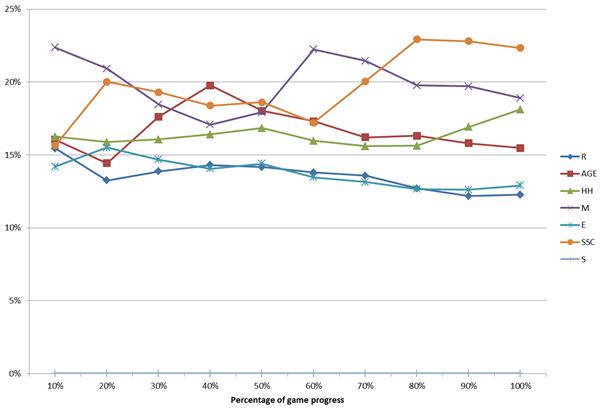
- A portfolio of the so-called strategies, which guide the Monte Carlo phase in the MCTS algorithm. In MINI-Player, seven strategies called: were implemented.
- Dynamic self-adaptation of the strategies based on their performance in a currently played game
- New method of parallelization of the MCTS/UCT algorithm in GGP
- A dedicated approach for single-player games
- A high-performance interpreter for the Game Description Language
- Communication module to take part in the GGP competition
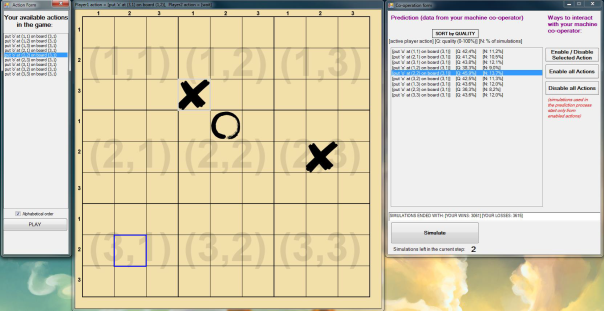
In order to illustrate the way the MCTS algorithm works, let us consider a game between two MCTS-based machine players in a well-known game of Connect-4. In each step, each of the players was allotted 7 second for a move. Four interesting steps were selected from the played game. The following figure shows snapshots of the game board taken in these four steps (after the move was performed). The statistics computed for each available action (move) just prior to the presented game positions are provided below in the text. Please note that Q and N denote the parameters from the UCT formula. The boundary values of Q are equal to 0 (expected loss for red) and 100 (expected victory for red), respectively.
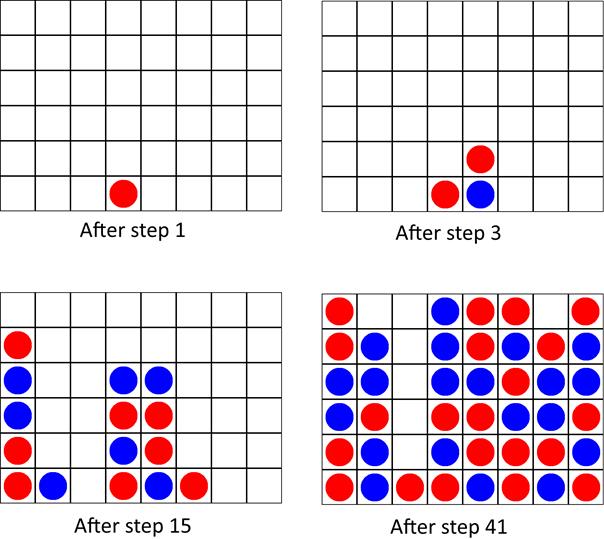
In step 1, two moves putting stones in the middlemost columns, i.e., 4 and 5, were clearly the best for the red player.
|
Action |
MCTS assessment (Q): |
The number of simulations (N): |
|
[Drop in column 1] |
50.0 |
2319 |
|
[Drop in column 2] |
53.3 |
3294 |
|
[Drop in column 3] |
58.4 |
6743 |
|
[Drop in column 4] |
61.7 |
12829 |
|
[Drop in column 5] |
61.4 |
11896 |
|
[Drop in column 6] |
57.4 |
5677 |
|
[Drop in column 7] |
52.5 |
3017 |
|
[Drop in column 8] |
50.8 |
2522 |
In step 3, the best strategy for red was to continue putting stones in the middle and block the blue player:
|
Action |
MCTS assessment (Q): |
The number of simulations (N): |
|
[Drop in column 1] |
56.1 |
6263 |
|
[Drop in column 2] |
55.9 |
6036 |
|
[Drop in column 3] |
54.4 |
4882 |
|
[Drop in column 4] |
59.3 |
11395 |
|
[Drop in column 5] |
59.7 |
12208 |
|
[Drop in column 6] |
53.1 |
4094 |
|
[Drop in column 7] |
55.4 |
5601 |
|
[Drop in column 8] |
53.9 |
4552 |
In step 15, the highest Q value was equal to 55.6, which means that the red player was slightly more likely to win, but the MCTS/UCT algorithm does not see any path leading to a very strong position (very likely victory) of this player (and of the other, as well):
|
Action |
MCTS assessment (Q): |
The number of simulations (N): |
|
[Drop in column 1] |
55.6 |
44908 |
|
[Drop in column 2] |
46.0 |
4945 |
|
[Drop in column 3] |
47.1 |
5788 |
|
[Drop in column 4] |
44.8 |
4241 |
|
[Drop in column 5] |
47.0 |
5737 |
|
[Drop in column 6] |
43.7 |
3679 |
|
[Drop in column 7] |
44.8 |
4205 |
|
[Drop in column 8] |
43.4 |
3547 |
Finally, in step 41, three out of four actions were assigned Q = 100 meaning that they lead to a victory for red. Only the last action resulted in an immediate win, but the length of a winning path makes no difference to the MCTS/UCT assessment.
|
Action |
MCTS assessment (Q): |
The number of simulations (N): |
|
[Drop in column 2] |
100.0 |
2567553 |
|
[Drop in column 3] |
26.3 |
259 |
|
[Drop in column 7] |
100.0 |
2567833 |
|
[Drop in column 8] |
100.0 |
2681408 |
Example games and selected results
As stated before, games in GGP are written in a GDL language. The language is based on Datalog and Prolog. Here, you can download [82KB] a compressed file with games used by us for the testing purposes.
The most famous public repositories can be found here:
http://www.ggp.org/view/tiltyard/games/
http://ggpserver.general-game-playing.de/ggpserver/public/show_games.jsp
http://arrogant.stanford.edu/ggp/php/showgames
The GGP competition is a specific testing environment as it is organized only once a year and very few matches between the players of a given match are carried out. Typically, a pair of GGP agents face each other from 2-4 times during a single day of the competition. Moreover, the choice of games is arbitrary and quite limited, so the luck/random factor plays a larger role than in a typical offline experiment with many repetitions. We have performed various experiments including MINI-Player that were carried out using 250 repetitions. We report the average scores obtained by MINI-Player, which is normalized into the [0,100] interval, where 0 is interpreted as a loss, 50 as a draw and 100 as a win of MINI-Player. Therefore, the higher the score, the better. For statistical significance we used the 95% confidence intervals computed from t-student distribution. They are presented as one number V, which should be interpreted that the score is burdened with the error of [–V, +V] with 95% statistical confidence.
TABLE 1
In the following table, the results achieved by MINI-Player against the basic implementation of the MCTS/UCT player are presented. Since the same basis is used in MINI-Player, the experiment reveals insights about the novel contributions, which are: portfolio of strategies and the mechanism of choosing a strategy for a simulation. Depending on the game, both players were given from 45 to 90 seconds for the initial analysis of the rules and from 10 to 30 seconds for making a move.
|
Game |
Score |
95% Confidence |
|
Alquerque |
67,2 |
4,12 |
|
Breakthrough |
46,8 |
6,19 |
|
Cephalopod Micro |
53,2 |
6,19 |
|
Checkers |
71,2 |
5,22 |
|
Chinese Checkers |
50,1 |
5 |
|
Chinook |
61,6 |
4,6 |
|
Connect Four |
58,6 |
5,62 |
|
Connect Four Suicide |
50,4 |
5,6 |
|
Farmers |
57,8 |
4,31 |
|
Farming Quandries |
78,6 |
3,66 |
|
Free for ALL 2P |
66,8 |
5,65 |
|
Hex |
50 |
6,2 |
|
Nine Board Tic-Tac-Toe |
67,8 |
5,42 |
|
Othello |
51 |
5,85 |
|
Pacman |
60,4 |
3,75 |
|
Pentago |
44 |
5,79 |
|
Pilgrimage |
55,8 |
3,12 |
|
Average: |
58,31 |
5,08 |